XML Scraping 101: ElementTree and namespaces
Written on November 13th, 2023 by Alvaro Carranza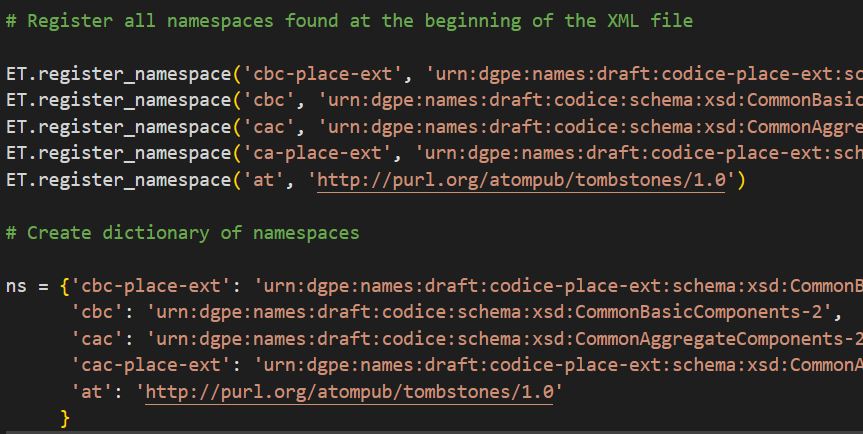
I am currently working on building a database with publicly available data on public procurement in Spain. I decided to work on this to make it easier to get insights on aggregated data, have access to data visualizations and other features on an easy-on-the-eyes dashboard, as the current data access is quite clunky.
To do so, I have started my Airflow journey with Marc Lamberti’s The Hands-On Guide and continued to hone my SQL skills with PostgreSQL Exercises. However, it all starts with actually getting the data.
Scraping is a great way to collect data when you don’t have access to structured sources (such as CSV files) or APIs. In this case, after trying to do some web scraping directly from the search tab of the website, I found the information on XML files (actually in ATOM, XML language used for web feeds): today’s blog entry will tackle XML scraping.
As can be seen after a quick google search on “namespaces beautifulsoup” in Stack Overflow, it seems that many users of BeautifulSoup, Python package for parsing HTML and thus useful for web scraping, struggle with namespaces while using it to parse an XML file. XML namespaces are used for providing uniquely named elements and attributes in an XML document. An XML instance may contain element or attribute names from more than one XML vocabulary. If each vocabulary is given a namespace, the ambiguity between identically named elements or attributes can be resolved. They can be found at the beginning of the file.

Namespaces found at the beginning of the XML file
While I am sure there is a way to do it with BS, after some research I decided to use ElementTree (ET), a library that allows you to parse and navigate a XML document by breaking it down in a tree structure that is easy to work with. Namespaces can be taken care of by registering them and creating a dictionary to call the appropriate namespace key in each .find() method so as to get the proper namespace value.
In the following code snippet I show this and an example of for loop to get the general information I found on the XML files for the previously mentioned project.
import os
import pandas as pd
import xml.etree.ElementTree as ET
# Replace with your file name or path
file_name = 'test.atom'
# Get the absolute path of the file
file_path = os.path.abspath(file_name)
# Parse the tree and get the root
tree = ET.parse(file_path)
root = tree.getroot()
# Register all namespaces found at the beginning of the XML file
ET.register_namespace('cbc-place-ext', 'urn:dgpe:names:draft:codice-place-ext:schema:xsd:CommonBasicComponents-2')
ET.register_namespace('cbc', 'urn:dgpe:names:draft:codice:schema:xsd:CommonBasicComponents-2')
ET.register_namespace('cac', 'urn:dgpe:names:draft:codice:schema:xsd:CommonAggregateComponents-2')
ET.register_namespace('ca-place-ext', 'urn:dgpe:names:draft:codice-place-ext:schema:xsd:CommonAggregateComponents-2')
ET.register_namespace('at', 'http://purl.org/atompub/tombstones/1.0')
# Create dictionary of namespaces
ns = {'cbc-place-ext': 'urn:dgpe:names:draft:codice-place-ext:schema:xsd:CommonBasicComponents-2',
'cbc': 'urn:dgpe:names:draft:codice:schema:xsd:CommonBasicComponents-2',
'cac': 'urn:dgpe:names:draft:codice:schema:xsd:CommonAggregateComponents-2',
'cac-place-ext': 'urn:dgpe:names:draft:codice-place-ext:schema:xsd:CommonAggregateComponents-2',
'at': 'http://purl.org/atompub/tombstones/1.0'
}
# Creating a Pandas dataframe with general info from the entries
ids = []
titles = []
summaries = []
links = []
statuses = []
for entry in root.findall('{http://www.w3.org/2005/Atom}entry'):
# General info
title = entry.find('{http://www.w3.org/2005/Atom}title').text
summary = entry.find('{http://www.w3.org/2005/Atom}summary').text
link = entry.find("{http://www.w3.org/2005/Atom}link").get("href")
details = entry.find('cac-place-ext:ContractFolderStatus', ns)
id = details.find('cbc:ContractFolderID', ns).text
status = details.find('cbc-place-ext:ContractFolderStatusCode', ns).text
ids.append(id)
titles.append(title)
summaries.append(summary)
links.append(link)
statuses.append(status)
general_data = {'id': ids,
'title': titles,
'summary': summaries,
'link': links,
'status': statuses
}
general_df = pd.DataFrame(general_data)
general_df
This dataframe (only using Pandas for intermediary work of course!) looks something like this (some Spanish text incoming):

I am currently finishing the last details to have all the information I am interested in and being able to scale it to the data of +10 years (33.5 gb). The actual code will most likely have tons of try clauses because trees evolve and don’t have the same branches/structure from one file to the other (and even from one entry to the other): data is indeed a beautiful soup.

