How to truly understand gradient descent... through neural networks
Written on December 12th, 2023 by Alvaro Carranza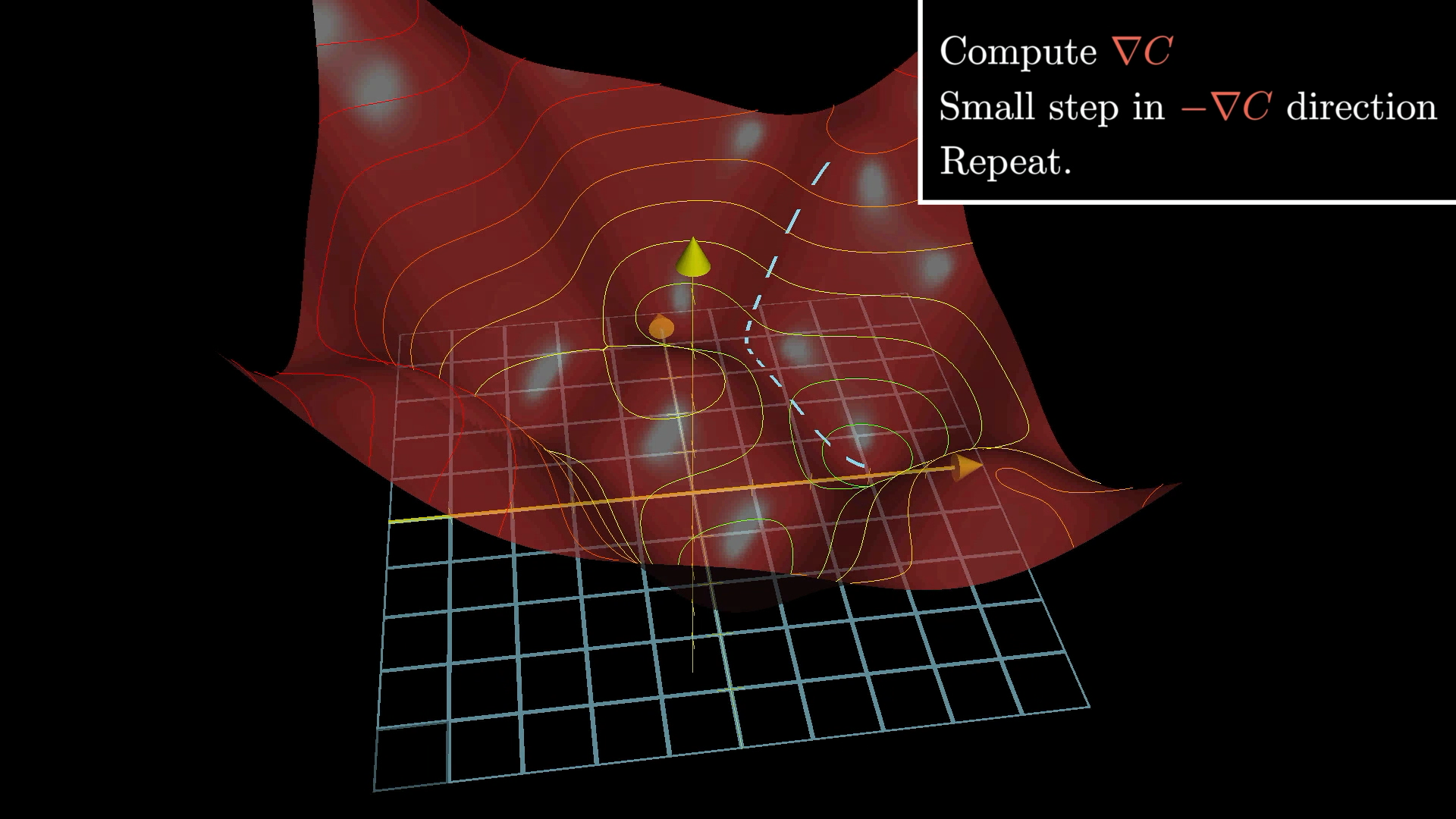
Image from 3Blue1Brown gradient descent lesson, which is just another great way to better understand gradient descent. Check him out if you haven’t yet! (source)
I have recently been studying a lot, not only Airflow as mentioned on my previous entry but also following Andrej Karpathy’s “Neural Networks: Zero to Hero” Youtube video series. I am writing and - most importantly - understanding the code necessary to build makemore, an autoregressive character-level language model, with a wide choice of models from bigrams all the way to a Transformer (exactly as seen in GPT).
However, I found it really interesting to have an aha moment when watching the first video of the series, which made me really understand gradient descent, even though it is one of the first optimization algorithm introduced to train machine learning. In this video he shows how to build micrograd, a small Autograd engine that implements backpropagation over a dynamically built DAG and a small neural networks library on top of it with a PyTorch-like API.

The aha moment came at 2:01:12, when Andrej shows gradient descent optimization manually, but honestly the whole two and a half hours is more than worth it. I won’t pretend I am able to explain it better than the man himself, so I will only repeat myself and wholeheartedly recommend to watch the video AND the full series.

